Using Machine Learning to Optimize Subscription Billing

As a data scientist at Recurly, my job is to use the vast amount of data that we have collected to build products that make subscription businesses more successful. One way to think about data science at Recurly is as an extended R&D department for our customers. We use a variety of tools and techniques, attack problems big and small, but at the end of the day, our goal is to put all of Recurly’s expertise to work in service of your business.
Managing a successful subscription business requires a wide range of decisions. What is the optimum structure for subscription plans and pricing? What are the most effective subscriber acquisition methods? What are the most efficient collection methods for delinquent subscribers? What strategies will reduce churn and increase revenue?
At Recurly, we're focused on building the most flexible subscription management platform, a platform that provides a competitive advantage for your business. We reduce the complexity of subscription billing so you can focus on winning new subscribers and delighting current subscribers.
Recently, we turned to data science to tackle a big problem for subscription businesses: involuntary churn.
The Problem: The Retry Schedule
One of the most important factors in subscription commerce is subscriber retention. Every billing event needs to occur flawlessly to avoid adversely impacting the subscriber relationship or worse yet, to lose that subscriber to churn.
Every time a subscription comes up for renewal, Recurly creates an invoice and initiates a transaction using the customer’s stored billing information, typically a credit card. Sometimes, this transaction is declined by the payment processor or the customer’s bank. When this happens, Recurly sends reminder emails to the customer, checks with the Account Updater service to see if the customer's card has been updated, and also attempts to collect payment at various intervals over a period of time defined by the subscription business. The timing of these collection attempts is called the “retry schedule.”
Our ability to correct and successfully retry these cards prevents lost revenue, positively impacts your bottom line, and increases your customer retention rate.
Other subscription providers typically offer a static, one-size-fits-all retry schedule, or leave the schedule up to the subscription business, without providing any guidance. In contrast, Recurly can use machine learning to craft a retry schedule that is tailored to each individual invoice based on our historical data with hundreds of millions of transactions. Our approach gives each invoice the best chance of success, without any manual work by our customers.
A key component of Recurly’s values is to test, learn and iterate. How did we call on those values to build this critical component of the Recurly platform?
Applying Machine Learning
We decided to use statistical models that leverage Recurly’s data on transactions (hundreds of millions of transactions built up over years from a wide variety of different businesses) to predict which transactions are likely to succeed. Then, we used these models to craft the ideal retry schedule for each individual invoice. The process of building the models is known as machine learning.
The term "machine learning" encompasses many different processes and methods, but at its heart is an effort to go past explicitly programmed logic and allow a computer to arrive at the best logic on its own.
While humans are optimized for learning certain tasks—like how children can speak a new language after simply listening for a few months—computers can also be trained to learn patterns. Aggregating hundreds of millions of transactions to look for the patterns that lead to transaction success is a classic machine learning problem.
A typical machine learning project involves gathering data, training a statistical model on that data, and then evaluating the performance of the model when presented with new data. A model is only as good as the data it’s trained on, and here we had a huge advantage.
Recurly’s Data Advantage
Recurly has records of hundreds of millions of credit card transactions dating back to 2009. We serve a breadth of subscription businesses, from boutique wine clubs to multinational SaaS companies. Our data includes transactions using all major credit card types as well as many alternative payment methods. Different currencies, gateways, countries… the list goes on and on.
A statistical model is only as good as its training data. The wide variety of data at our disposal is any data scientist’s dream. Companies with a large number of subscribers can certainly build these sorts of models based on their own data, but we believe that aggregating the data from many subscription companies results in a more robust model.
Once the data has been gathered and cleaned, the work of training the model begins. We have one dependent variable (whether or not a transaction succeeds) and dozens of independent variables (like the day of week, the credit card brand, etc.). The model then assesses which of the independent variables has the most impact on transaction success.
Once the model has been trained, we validate the model by using other data that wasn’t in our training set. It’s crucially important to train and test on different data, because the model must be robust enough to make accurate predictions about data it has never seen before.
To do so, we take transactions where we already know whether they succeeded or failed and ask the model the odds of those transactions succeeding. For a batch of transactions that we know contained 80% successful transactions, the model should predict that those transactions will succeed 80% of the time.
Choosing a Model
We started with a simple Logistic Regression model, which performed well. However, logistic regression tends to work best when you have mostly continuous variables (like the dollar amount of a transaction), but we had mostly categorical variables (as in, this transaction was on a credit or a debit card).
While it was great to know that we were onto something and that transaction success is predictable, how could we iterate and build a better model? We tried a Random Forest model, which performs better with categorical variables.
So what is a Random Forest model? You may be familiar with a decision tree:
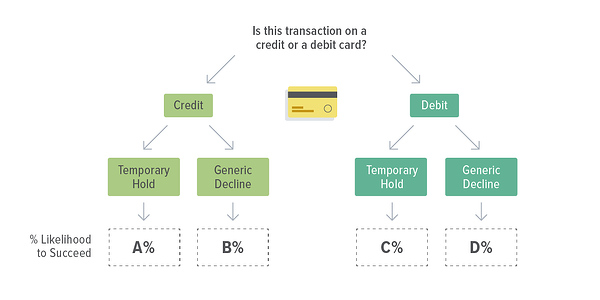
We can build a decision tree based on our training data. Is this transaction on a credit card? Then adjust the transaction success likelihood by X%. Is the transaction on a Wednesday at 3pm? Adjust by Y%. And so on and so on.
We could make a decision tree that perfectly accounts for every transaction in the training data. But its accuracy would be much worse when applied to the testing data. This problem is known as “overfitting” or building a model that is too specific and won’t generalize.
What if we could aggregate the results from multiple decision trees? Think about an interview panel. Your company probably shouldn’t make the decision to hire a candidate based on only one interviewer’s opinion. You want multiple interviewers, each asking their own questions. The interviewers make their individual decisions, then come together to make a collective decision whether to hire the candidate.
We can use a similar process for decision trees. We can create many decision trees, train them on random subsets of the data, and use the majority vote of the trees to make our prediction. This ensemble of trees is known as a Random Forest model.
We trained a Random Forest model on our hundreds of millions of transactions to predict the probability of any given transaction succeeding. What if we retried this Visa debit card transaction on Wednesday at 2pm or Thursday at 9am? Our model can tell us which potential attempt is more likely to succeed, with high accuracy. Starting with a dataset that includes so many different types of transactions allows us to make these predictions accurately.
Operationalizing the Random Forest
Having a robust model is great, but this isn’t just an academic exercise. Next, we need to make the model’s recommendations a part of our product.
Let’s say that a Recurly customer has decided to give us a 20-day window to collect on each subscription invoice that fails. We can look at many theoretical transactions within that window, pick the transaction most likely to succeed according to the model, and schedule the retry then.
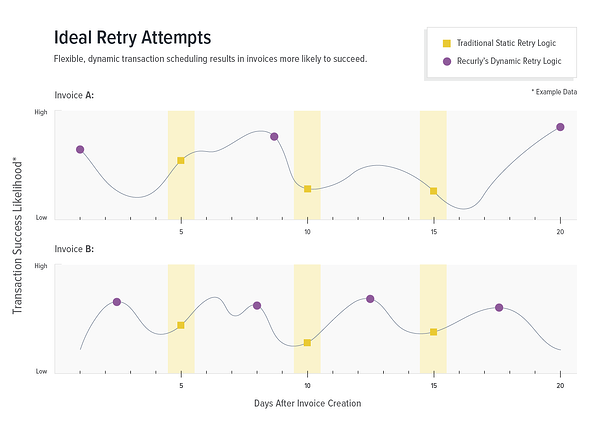
The result is a retry schedule for a failed invoice that is individually tailored to that invoice. Rather than a static “one size fits all” schedule or a complicated system that you have to set up and track yourself, Recurly compares each potential transaction to the hundreds of millions of transactions that we've already seen and picks the ideal retry schedule for each individual case.
Having an optimized retry schedule also means that the time between the initial failure and the subsequent success gets shorter. We call this the "time to collect." This is really important because most businesses choose to keep the subscriber "active" while their invoice is past due, continuing to provide products or services. The longer those delinquent accounts remain active, the higher the cost of goods sold (COGS). This is especially important for OTT companies. Minimizing the time to collect saves money, and it is a closely-tracked metric.
Along with the new models, we also built a new experimental infrastructure to deploy these models and A/B test the results quickly and accurately. This allows us to continue the test-learn-iterate cycle so Recurly customers continue to grow.
We have a lot more to say about the role of machine learning at Recurly and the gains that we’re making for our customers. Stay tuned!






